The combination of rising temperatures and industrial chemicals in our water is creating a lot of algae. Bloom thinks it has a solution to clean up our lakes—and make products in the process.
 |
| Bloom uses custom technology to carefully harvest wild algae from the water. |
 |
| There, they collect algae from the top six inches or so of the water column. |
 |
| The design, with screens and gentle suction, can't harm wildlife in the water. |
Looking at the thick green layer of slime on some Florida beaches, most people see only the environmental crisis: out-of-control algae, fed by human activity and climate change, are killing fish, manatees, and other underwater life. Rob Falken sees a solvable problem and your next pair of shoes.
 |
Along with the algae, the harvester also removes nitrogen and phosphorus.
|
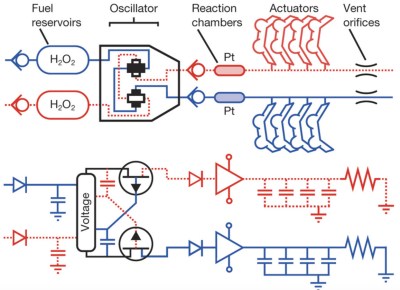
Bloom, Falken's startup, uses custom technology to carefully harvest wild algae from the water, and then transforms it into a raw material to make plastics and foams for use in clothing, sneakers, car upholstery, and other products. The first product—a foam traction pad for surfboards, made with Kelly Slater—will hit shelves on October 1.
All of those products are typically made from petroleum formed into tiny pellets. Bloom makes pellets from algae instead, solar-drying the algae into flakes, pulverizing the flakes into a powder, and then turning that powder into pellets that can be melted down to merge with the petroleum-based ingredients. By partially replacing the pellets made from fossil fuels—and by sucking up carbon as it grows—the algae also helps lower carbon footprints.
"The end goal is to remove as much of the petroleum feedstock as possible," says Falken. "When you take a waste stream from nature—there naturally but there in such mass because of man made inputs—we can take that feedstock, that problem, and functionalize it into usable goods that are the exact same quality, indistinguishable, from the status quo that's out there today."
The company's small mobile harvesting units sit at the edge of a pond or lake, or float on a pontoon in the ocean, and collect algae from the top six inches or so of the water column.
 |
| The company's small mobile harvesting units sit at the edge of a pond or lake, or float on a pontoon in the ocean. |
"The harvester works like a giant vacuum, basically," Falken says. The design, with screens and gentle suction, can't harm wildlife in the water; the technology was used first at catfish farms, where sucking up a fish with the algae would be an obvious problem.
Along with the algae, the harvester also removes nitrogen and phosphorus—excess fertilizers that end up in the water from farming, sewage overflows, or lawns, and help cause the algae growth in the first place. Pure, filtered water is returned to the body of water.
In Florida, where officials declared a state of emergency in several counties because of algae blooms this summer, much of the problem comes from giant Lake Okeechobee, where runoff from sugar cane plantations and cattle farms fills the lake with algae-boosting fertilizer. Infrastructure and development in the area have made the problem worse. After heavy rains, the state flushes the algae-filled water out through canals, and it ends up also harming beaches at the coasts.
As the algae proliferate in the water, they can cut off oxygen. When the growth is out of control, and the algae die, they release toxins called microcystins that can last for weeks or months.
Bloom hopes to control the problem in Florida—and many other places struggling with algae—by regularly harvesting algae before it reaches a toxic state, and clearing out the fertilizers that cause future overgrowth. While the company can clean out toxic algae, only healthy algae is usable, so it's better to catch the problem before it escalates.
"When you have an algae crisis today, that's because of a lot of negligence, that's because nobody's doing anything to remove the inputs of nitrogen and phosphorus, and there's a massive influx of those inputs running rampant," says Falken. "You also couple that with an extremely high heat index and you've got a perfect storm."
The company has been operating in China at Lake Taihu—an even larger lake than Okeechobee that millions of people rely on for drinking water—for two years, where the company says they have removed millions of pounds of algae.
Now, they're in meetings with Florida officials, along with the infrastructure company AECOM, to make a plan for demonstrating the technology in the state. They hope to begin regularly working at Lake Okeechobee.
While other companies grow algae in tanks, wild harvesting has advantages—the process solves an environmental problem, and doesn't require the energy and cost used to grow algae in the dark. Algae grown in tanks is also genetically engineered, and Bloom argues that it could wipe out natural strains if it escaped into the wild.
The algae-based feedstock can be dropped into current manufacturing without any changes, and the cost is the same as petroleum-based feedstocks on the market today. "We can't convert industries worldwide if the price is higher," Falken says.
 |
| Then it transforms it into a raw material to make plastics and foams for use in clothing, sneakers, car upholstery, and other products. |
There's also no shortage of wild algae, especially as warming waters make the problem worse. "We've already got more algae than we'll ever need," he says. "In China, Lake Taihu could produce enough algae for us to produce a pair of shoes for every man, woman, and child on this planet."
Even as some governments try to address the larger problems—Florida, for example, plans to spend more than $1 billion buying land to create storage ponds in the hope of naturally treating water—the process isn't guaranteed to work, and will take time.
"Those inputs are not going away," says Falken. "Agriculture's not going away, sugar cane plantations aren't going away, people are not going to en masse stop using fertilizers on their lawn. It's unfortunate. We can educate as much as possible, but the reality here is someone has got to be proactive. Because we can do something with it, and do a lot of good with it, we can ensure that algal bloom crisis is in time a thing of the past."
They hope to use the algae harvesters all over the country and world. "You look at Florida and say that's the epicenter, that's where the crisis is worst because all of the water policy issues and all the negligence," he says. "But if you look at the U.S. as a whole, all 50 states have algal bloom in some semi-crisis mode right now. You've got about 20 states that are really at peak crisis. The algae is everywhere, and the problems are global."
ORIGINAL: Fast Company
09.29.16