3D printed master molds have been used to create microfluidic LEGO bricks that facilitate the study of liquid flow for medical research. The LEGO brick method is being explored by the Department of Biomedical Engineering at the University of California, Irvine, with findings published in the Journal of Micromechanics and Microengineering, January 2017.
What is microfluidics?
Microfluidics is the manipulation and study of sub-microscopic litres of liquid. In a device such as the University of California’s LEGO bricks, liquids are channelled through empty vessels spanning no more than 500 μm (microns, for comparison: a human hair is 50 μm in diameter).
Testing the flow of liquids through the LEGO bricks with colored inks. Image via: Kevin Vittayarukskul and Abraham Phillip Lee
The way a liquid behaves during a flow, and when mixed with other nanoliquids tells researchers certain things about its biological behaviour, Microfludics can also be controlled in a way to produce autonomous movement, as in the example of Harvard University’s soft-robotic Octobot.
Moving .gif shows Harvard’s Octobot that harnesses microfluidic principles to move. Clip via: @NatureNews
In biomedical research microfluidic chips are used to conduct assays that test the reactions between substances, as in lab-on-a-chip technology. Using these devices is preferable to some traditional assay methods as the microscale parts consume less time and resources. California’s LEGO bricks seek to promote these qualities by providing more recognisable devices that are also capable of being mass produced.
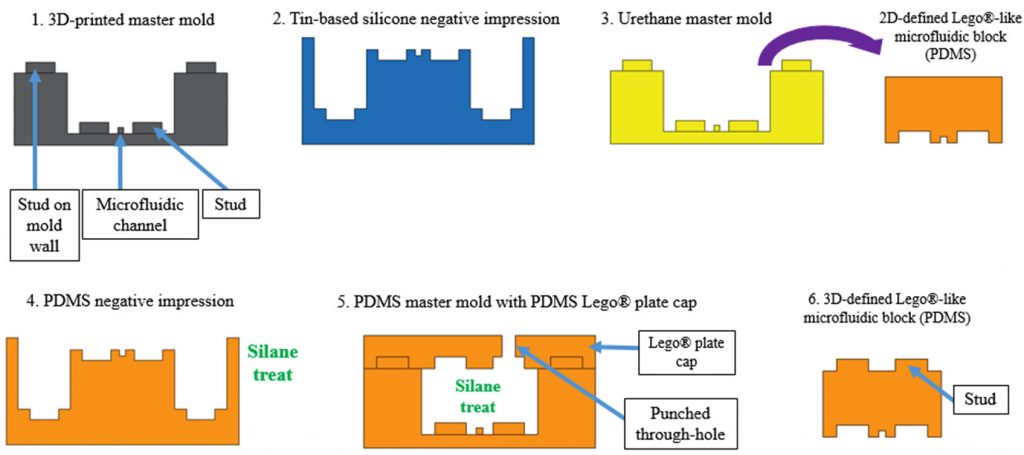
Making the microfluidic LEGO bricks Kevin Vittayarukskul and Professor Abraham Lee’s approach uses Autodesk’s AutoCAD software to first design blocks with an embedded microfluidic channel.
From this a mold is also designed, and then 3D printed on a Perfactory 3 Mini 3D printer by EnvisionTEC that uses the DLP method of vat polymerisation to cure the material. PDMS, (Polydimethylsiloxane) a silicone-based polymer is then used to cast the LEGO bricks.
Process of making the microfluidic LEGO mold. Image via: Kevin Vittayarukskul and Abraham Phillip Lee
The properties of PDMS make it naturally transparent and biocompatible, which is ideal for this kind of research. It is also known for its ability to exactly match the shape of a cast into which it is poured, meaning that none of the DLP 3D printed quality is lost on the final cast.
A microfluidic LEGO kit? The advantages of being able to stack the microfluidic blocks is that researchers can combine even more channels into a single space. It also allows easy assembly of varying channels, i.e. one straight vessel in to a winding one.
Using a tried and tested building block such as a LEGO brick also means that it has great potential for mass-production. The case with medical research is that it often isn’t accessible by other scholars that could make use of the technology. But a microfluidic LEGO kit could be just the ticket to encourage future biomedical research.
Speaking to EE Times Europe A truly LEGO®-like modular microfluidics platform co-author Professor Abraham Lee explains:
The main goal of this project was to train and educate the next generation of microfluidic developers and researchers. By using actual LEGO’s as the building block and assembly platform, our hope was to attract students as early as young as high schoolers to be interested in the field, learn about microfluidics and stimulate their imagination for new products for applications over a very wide range.
Testing the flow of liquids through the LEGO bricks with colored inks. Image via: Kevin Vittayarukskul and Abraham Phillip Lee
A truly Lego®-like modular microfluidics platform Kevin Vittayarukskul and Abraham Phillip Lee
Beau Jackson Writer based in London, originally from Yorkshire. Fan of lab-on-a-chip
technology, microfluidics, scanning, tech-inspired art and 3D Benchy. January 25, 2017
More and more of our waterways are being starved of life through pollution. One simple, yet improbable, solution? Cover rafts in plants.
In the shallow waters of Gijon harbour, in northern Spain, swims scientists' latest weapon in the war against pollution.
Just five years ago, Fish Fry Lake was dying. The groundwater flowing into the lake situated 30 miles northeast of Billings, Montana, contained high levels of nitrogen and phosphorous, common ingredients in agricultural fertilisers and animal waste. The nitrogen and phosphorus had fostered an overgrowth of algae, which covered the lake and blocked sunlight from penetrating the surface. The deep water was a dead zone, devoid of oxygen and home to very little aquatic life.
The solution was as simple as it was improbable: cover rafts with plants, and set them afloat in the lake. Within a year-and-a-half, the algal blooms were gone. Water clarity improved. Oxygen levels rose. Today, the lake is home to a thriving community of fish, including black crappie, yellow perch and Yellowstone cutthroat trout.
The story of Fish Fry Lake demonstrates the power of mimicking wetlands to clean up dirty waterways. Wetlands are sometimes called nature’s own water purifiers: as dirty water moves through a sprawling marsh, the bacteria that cling to wetland plants, timber, rocks, and other debris consume and process some common water pollutants. Other contaminants get trapped in the mud and muck. As result of these and other processes, the water that eventually flows out of a wetland is much cleaner than the stream that came trickling in.
By creating floating treatment wetlands out of small, human-engineered rafts of vegetation, researchers and entrepreneurs hope to provide these same ecological services to small, polluted bodies of water that may be far from a natural marsh. “BioHaven floating islands are concentrated wetland systems that are essentially biomimicking nature’s wetland effect,” says Bruce Kania, the founder and research director of Floating Island International, the company behind the Fish Fry Lake rafts.
ORIGINAL: Floating Island International
Cleansing power
To construct a BioHaven island, the company starts with layers of mesh made from recycled plastic. They assemble this mesh into a floating raft – which can be as small as a home aquarium or nearly as large as a football field – and top it with soil and plants. They launch the island into a lake, pond, stream, or lagoon, anchoring it in place. Over time, the plants’ roots grow into and through the raft’s porous matrix, descending into the water below. At the same time, bacteria colonise the island, assembling into sticky, slimy sheets called biofilm that coat the floating matrix and the suspended plant roots.
This bacterial biofilm is the secret to a floating island’s cleansing power. Overgrowth of algae from nitrogen and phosphorus pollution can cause several problems, preventing sunlight from reaching subaquatic plants and starving a body of water of the oxygen needed to sustain fish populations and other animal life. A dead zone, like the one is Fish Fry Lake, is often the ultimate result. The biofilm bacteria consume nitrogen and phosphorous, however, and as polluted water flows through and around a floating island, the bacteria converts these contaminants into less harmful substances. Though the bacteria do the brunt of the work, the plant roots suspended from the floating island also play their part, absorbing some of the nitrogen and phosphorous through their roots.
In Fish Fry Lake, for instance, Floating Island International deployed several islands, which together covered almost 2% of the lake’s 6.5-acre (2.6-hectare) surface area. Over the course of four years, the islands helped reduce nitrogen concentrations by 95% and phosphorus concentrations by nearly 40%. Today, levels of dissolved oxygen are sixty times what they once were.
Clearer, cleaner, healthier
The system also mechanically filters out other pollutants, like metals and particulates. “The sticky biofilm essentially keeps the water clear because all the suspended solids tend to bond to it,” says Kania. Floating Island International, which has deployed more than 4,400 of their artificial wetland systems worldwide, has documented this effect in multiple case studies. For example, the concentrations of suspended solids, copper, lead, zinc, and oil and grease fell dramatically after a floating island was installed in a stormwater pond in Montana. Controlled laboratory studies and research by scientists not affiliated with the company havealsofoundthat floating treatment wetlands can reduce the levels of many common water pollutants.
Some scientists are now exploring how to optimise the design of floating islands – probing, for instance, which plants do the best job of removing pollutants. Gary Burtle, an aquaculture specialist at the University of Georgia, thinks we can get even more out of these artificial wetlands by seeding the rafts with plants that are of commercial value, such as lettuces and herbs. Burtle is screening a number of potential plant candidates – if he finds one that grows well on a floating island, we may soon see constructed wetland systems that “give us a little bit more return”, he says, producing saleable crops while purifying the water.
Meanwhile, the removal of contaminants not only improves the water itself, but also helps to foster a healthier ecosystem. Clearer water allows light to penetrate deeper, encouraging the growth of various aquatic plants, which produce oxygen and become part of the food chain, supporting larger populations of fish and other animals. “You end up with a waterway that can be abundant,” Kania says, “that can be verdant even at depth.” The organic debris that attaches itself to the underside of a floating island also becomes a source of food for fish and other aquatic organisms, and the island itself provides new habitat for birds.
“The concept of how to get back to a healthy waterway,” Kania says, “is very simple: nature’s wetland effect.” All we have to do is simulate it.
How to design materials with reprogrammable shape and function
Harvard researchers have developed a general framework to design reconfigurable metamaterials that is scale independent, meaning it can be applied to everything from meter-scale architectures to reconfigurable nano-scale systems (Image courtesy of Johannes Overvelde/Harvard SEAS).
Metamaterials — materials whose function is determined by structure, not composition — have been designed to
bend light and sound,
transform from soft to stiff, and
even dampen seismic waves from earthquakes.
But each of these functions requires a unique mechanical structure, making these materials great for specific tasks, but difficult to implement broadly.
But what if a material could contain within its structure, multiple functions and easily and autonomously switch between them?
“In terms of reconfigurable metamaterials, the design space is
incredibly large and so the challenge is to come up with smart
strategies to explore it,” said Katia Bertoldi,
John L. Loeb Associate Professor of the Natural Sciences at SEAS and
senior author of the paper. “Through a collaboration with designers and
mathematicians, we found a way to generalize these rules and quickly
generate a lot of interesting designs.”
Bertoldi and former graduate student Johannes Overvelde, who is the first author of the paper, collaborated with Chuck Hoberman, of the Harvard Graduate School of Design (GSD) and associate faculty at the Wyss and James Weaver, a senior research scientist at the Wyss, to design the metamaterial.
The research began in 2014, when Hoberman showed Bertoldi his original designs for a family of foldable structures, including a prototype of an extruded cube. “We were amazed by how easily it could fold and change shape,” said Bertoldi. “We realized that these simple geometries could be used as building blocks to form a new class of reconfigurable metamaterials but it took us a long time to identify a robust design strategy to achieve this.”
The interdisciplinary team realized thatassemblies of polyhedra can be used as a template to design extruded reconfigurable thin-walled structures, dramatically simplifying the design process.
“By combining design and computational modeling, we were able to identify a wide range of different rearrangements and create a blueprint or DNA for building these materials in the future, ” said Overvelde, now scientific group leader of the Soft Robotic Matter group at FOM Institute AMOLF in the Netherlands.
The same computational models can also be used to quantify all the different ways in which the material could bend and how that affected effective material properties like stiffness. This way they could quickly scan close to a million different designs, and select those with the preferred response.
Once a specific design was selected, the team constructed working prototypes of each 3D metamaterial both using laser-cut cardboard and double-sided tape, and multimaterial 3D printing. Like origami, the resulting structure can be folded along their edges to change shape.
“Now that we’ve solved the problem of formalizing the design, we can start to think about new ways to fabricate and reconfigure these metamaterials at smaller scales, for example through the development of 3D-printed self actuating environmentally responsive prototypes,” said Weaver.
This formalized design framework could be useful for
structural and aerospace engineers,
material scientists,
physicists,
robotic engineers,
biomedical engineers,
designers and
architects.
“This framework is like a toolkit to build reconfigurable materials,” said Hoberman. “These building blocks and design space are incredibly rich and we’ve only begun to explore all the things you can build with them.”
This work was supported by the Materials Research Science and Engineering Center and the National Science Foundation. ORIGINAL:Harvard SEAS
By Leah Burrows
January 18, 2017
These technologies all have staying power. They will affect the economy and our politics, improve medicine, or influence our culture. Some are unfolding now; others will take a decade or more to develop. But you should know about all of them right now.
This illustration shows the possible surface of TRAPPIST-1f, one of the newly discovered planets in the TRAPPIST-1 system. Scientists using the Spitzer Space Telescope and ground-based telescopes have discovered that there are seven Earth-size planets in the system.
NASA's Spitzer Space Telescope has revealed the first known system of seven Earth-size planets around a single star. Three of these planets are firmly located in the habitable zone, the area around the parent star where a rocky planet is most likely to have liquid water.
The discovery sets a new record for greatest number of habitable-zone planets found around a single star outside our solar system. All of these seven planets could have liquid water – key to life as we know it – under the right atmospheric conditions, but the chances are highest with the three in the habitable zone.
“This discovery could be a significant piece in the puzzle of finding habitable environments, places that are conducive to life,” said Thomas Zurbuchen, associate administrator of the agency’s Science Mission Directorate in Washington. “Answering the question ‘are we alone ?’ is a top science priority and finding so many planets like these for the first time in the habitable zone is a remarkable step forward toward that goal.”
Seven Earth-sized planets have been observed by NASA's Spitzer Space Telescope around a tiny, nearby, ultra-cool dwarf star called TRAPPIST-1. Three of these planets are firmly in the habitable zone.
Credits: NASA
The TRAPPIST-1 star, an ultra-cool dwarf, has seven Earth-size planets orbiting it. This artist's concept appeared on the cover of the journal Nature on Feb. 23, 2017.
Credits: NASA/JPL-Caltech
At about 40 light-years (235 trillion miles) from Earth, the system of planets is relatively close to us, in the constellation Aquarius. Because they are located outside of our solar system, these planets are scientifically known as exoplanets.
This exoplanet system is called TRAPPIST-1, named for The Transiting Planets and Planetesimals Small Telescope (TRAPPIST) in Chile. In May 2016, researchers using TRAPPIST announced they had discovered three planets in the system. Assisted by several ground-based telescopes, including the European Southern Observatory's Very Large Telescope, Spitzer confirmed the existence of two of these planets and discovered five additional ones, increasing the number of known planets in the system to seven.
The new results were published Wednesday in the journal Nature, and announced at a news briefing at NASA Headquarters in Washington.
Using Spitzer data, the team precisely measured the sizes of the seven planets and developed first estimates of the masses of six of them, allowing their density to be estimated.
Based on their densities, all of the TRAPPIST-1 planets are likely to be rocky. Further observations will not only help determine whether they are rich in water, but also possibly reveal whether any could have liquid water on their surfaces. The mass of the seventh and farthest exoplanet has not yet been estimated – scientists believe it could be an icy, "snowball-like" world, but further observations are needed.
"The seven wonders of TRAPPIST-1 are the first Earth-size planets that have been found orbiting this kind of star," said Michael Gillon, lead author of the paper and the principal investigator of the TRAPPIST exoplanet survey at the University of Liege, Belgium. "It is also the best target yet for studying the atmospheres of potentially habitable, Earth-size worlds."
This artist's concept shows what each of the TRAPPIST-1 planets may look like, based on available data about their sizes, masses and orbital distances.
Credits: NASA/JPL-Caltech
In contrast to our sun, the TRAPPIST-1 star – classified as an ultra-cool dwarf – is so cool that liquid water could survive on planets orbiting very close to it, closer than is possible on planets in our solar system. All seven of the TRAPPIST-1 planetary orbits are closer to their host star than Mercury is to our sun. The planets also are very close to each other. If a person was standing on one of the planet’s surface, they could gaze up and potentially see geological features or clouds of neighboring worlds, which would sometimes appear larger than the moon in Earth's sky.
The planets may also be tidally locked to their star, which means the same side of the planet is always facing the star, therefore each side is either perpetual day or night. This could mean they have weather patterns totally unlike those on Earth, such as strong winds blowing from the day side to the night side, and extreme temperature changes.
Spitzer, an infrared telescope that trails Earth as it orbits the sun, was well-suited for studying TRAPPIST-1 because the star glows brightest in infrared light, whose wavelengths are longer than the eye can see. In the fall of 2016, Spitzer observed TRAPPIST-1 nearly continuously for 500 hours. Spitzer is uniquely positioned in its orbit to observe enough crossing – transits – of the planets in front of the host star to reveal the complex architecture of the system. Engineers optimized Spitzer’s ability to observe transiting planets during Spitzer’s “warm mission,” which began after the spacecraft’s coolant ran out as planned after the first five years of operations.
"This is the most exciting result I have seen in the 14 years of Spitzer operations," said Sean Carey, manager of NASA's Spitzer Science Center at Caltech/IPAC in Pasadena, California. "Spitzer will follow up in the fall to further refine our understanding of these planets so that the James Webb Space Telescope can follow up. More observations of the system are sure to reveal more secrets.”
Following up on the Spitzer discovery, NASA's Hubble Space Telescope has initiated the screening of four of the planets, including the three inside the habitable zone. These observations aim at assessing the presence of puffy, hydrogen-dominated atmospheres, typical for gaseous worlds like Neptune, around these planets.
This 360-degree panorama depicts the surface of a newly detected planet, TRAPPIST 1-d, part of a seven planet system some 40 light years away. Explore this artist’s rendering of an alien world by moving the view using your mouse or your mobile device.
Credits: NASA
In May 2016, the Hubble team observed the two innermost planets, and found no evidence for such puffy atmospheres. This strengthened the case that the planets closest to the star are rocky in nature.
"The TRAPPIST-1 system provides one of the best opportunities in the next decade to study the atmospheres around Earth-size planets," said Nikole Lewis, co-leader of the Hubble study and astronomer at the Space Telescope Science Institute in Baltimore, Maryland. NASA's planet-hunting Kepler space telescope also is studying the TRAPPIST-1 system, making measurements of the star's minuscule changes in brightness due to transiting planets. Operating as the K2 mission, the spacecraft's observations will allow astronomers to refine the properties of the known planets, as well as search for additional planets in the system. The K2 observations conclude in early March and will be made available on the public archive.
This poster imagines what a trip to TRAPPIST-1e might be like.
Credits: NASA/JPL-Caltech
Spitzer, Hubble, and Kepler will help astronomers plan for follow-up studies using NASA's upcoming James Webb Space Telescope, launching in 2018. With much greater sensitivity, Webb will be able to detect the chemical fingerprints of water, methane, oxygen, ozone, and other components of a planet's atmosphere. Webb also will analyze planets' temperatures and surface pressures – key factors in assessing their habitability.
NASA’s Jet Propulsion Laboratory (JPL) in Pasadena, California, manages the Spitzer Space Telescope mission for NASA's Science Mission Directorate. Science operations are conducted at the Spitzer Science Center, at Caltech, in Pasadena, California. Spacecraft operations are based at Lockheed Martin Space Systems Company, Littleton, Colorado. Data are archived at the Infrared Science Archive housed at Caltech/IPAC. Caltech manages JPL for NASA.
A new brain mechanism hiding in plain sight. Researchers have discovered a brand new mechanism that controls the way nerve cells in our brain communicate with each other to regulate learning and long-term memory.
The fact that a new brain mechanism has been hiding in plain sight is a reminder of how much we have yet to learn about how the human brain works, and what goes wrong in neurodegenerative disorders such as Alzheimer's and epilepsy.
"These discoveries represent a significant advance and will have far-reaching implications for the understanding of
"We believe that this is a groundbreaking study that opens new lines of inquiry which will increase understanding of the molecular details of synaptic function in health and disease."
The human brain contains around 100 billion nerve cells, and each of those makes about 10,000 connections - known as synapses - with other cells.
That's a whole lot of connections, and each of them is strengthened or weakened depending on different brain mechanisms that scientists have spent decades trying to understand.
Until now, one of the best known mechanisms to increase the strength of information flow across synapses was known as LTP, or long-term potentiation.
LTP intensifies the connection between cells to make information transfer more efficient, and it plays a role in a wide range of neurodegenerative conditions -
too much LTP, and you risk disorders such as epilepsy,
too little, and it could cause dementia or Alzheimer's disease.
As far as researchers were aware, LTP is usually controlled by the activation of special proteins called NMDA receptors.
But now the UK team has discovered a brand new type of LTP that's regulated in an entirely different way.
After investigating the formation of synapses in the lab, the team showed that this new LTP mechanism is controlled by molecules known as kainate receptors, instead of NMDA receptors.
"These data reveal a new and, to our knowledge, previously unsuspected role for postsynaptic kainate receptors in the induction of functional and structural plasticity in the hippocampus," the researchers write in Nature Neuroscience.
This means we've now uncovered a previously unexplored mechanism that could control learning and memory.
"Untangling the interactions between the signal receptors in the brain not only tells us more about the inner workings of a healthy brain, but also provides a practical insight into what happens when we form new memories," said one of the researchers,Milos Petrovic from the University of Central Lancashire.
"If we can preserve these signals it may help protect against brain diseases."
Not only does this open up a new research pathway that could lead to a better understanding of how our brains work, but if researchers can find a way to target these new pathways, it could lead to more effective treatments for a range of neurodegenerative disorders.
It's still early days, and the discovery will now need to be verified by independent researchers, but it's a promising new field of research.
"This is certainly an extremely exciting discovery and something that could potentially impact the global population," said Petrovic.
Strange microbes have been found inside the massive, subterranean crystals of Mexico's Naica Mine, and researchers suspect they've been living there for up to 50,000 years.
The ancient creatures appear to have been dormant for thousands of years, surviving in tiny pockets of liquid within the crystal structures. Now, scientists have managed to extract them - and wake them up.
The Cave of Crystals in Mexico's Naica Mine might look incredibly beautiful, but it's one of the most inhospitable places on Earth, with temperatures ranging from 45 to 65°C (113 to 149°F), and humidity levels hitting more than 99 percent.
Not only are temperatures hellishly high, but the environment is also oppressively acidic, and confined to pitch-black darkness some 300 metres (1,000 feet) below the surface.
In lieu of any sunlight, microbes inside the cave can't photosynthesise - instead, they perform chemosynthesis using minerals like iron and sulphur in the giant gypsum crystals, some of which stretch 11 metres (36 feet) long, and have been dated to half a million years old.
Researchers have previously found life living inside the walls of the cavern and nearby the crystals -a 2013 expedition to Naica reported the discovery of creatures thriving in the hot, saline springs of the complex cave system.
But when Boston and her team extracted liquid from the tiny gaps inside the crystals and sent them off to be analysed, they realised that not only was there life inside, but it was unlike anything they'd seen in the scientific record.
They suspect the creatures had been living inside their crystal castles for somewhere between 10,000 and 50,000 years, and while their bodies had mostly shut down, they were still very much alive.
"Other people have made longer-term claims for the antiquity of organisms that were still alive, but in this case these organisms are all very extraordinary - they are not very closely related to anything in the known genetic databases," Boston told Jonathan Amos at BBC News.
What's perhaps most extraordinary about the find is that the researchers were able to 'revive' some of the microbes, and grow cultures from them in the lab.
"Much to my surprise we got things to grow," Boston told Sarah Knapton at The Telegraph. "It was laborious. We lost some of them - that's just the game. They've got needs we can't fulfil."
At this point, we should be clear that the discovery has yet to be published in a peer-reviewed journal, so until other scientists have had a chance to examine the methodology and findings, we can't consider the discovery be definitive just yet.
The team will also need to convince the scientific community that the findings aren't the result of contamination - these microbes are invisible to the naked eye, which means it's possible that they attached themselves to the drilling equipment and made it look like they came from inside the crystals.
"I think that the presence of microbes trapped within fluid inclusions in Naica crystals is in principle possible," Purificación López-García from the French National Centre for Scientific Research, who was part of the 2013 study that found life in the cave springs, told National Geographic.
"[But] contamination during drilling with microorganisms attached to the surface of these crystals or living in tiny fractures constitutes a very serious risk," she says. I am very skeptical about the veracity of this finding until I see the evidence."
That said, microbiologist Brent Christner from the University of Florida in Gainesville, who was also not involved in the research, thinks the claim isn't as far-fetched as López-García is making it out to be, based on what previous studies have managed with similarly ancient microbes.
"[R]eviving microbes from samples of 10,000 to 50,000 years is not that outlandish based on previous reports of microbial resuscitations in geological materials hundreds of thousands to millions of years old," he told National Geographic.
For their part, Boston and her team say they took every precaution to make sure their gear was sterilised, and cite the fact that the creatures they found inside the crystals were similar, but not identical to those living elsewhere in the cave as evidence to support their claims.
"We have also done genetic work and cultured the cave organisms that are alive now and exposed, and we see that some of those microbes are similar but not identical to those in the fluid inclusions," she said.
Only time will tell if the results will bear out once they're published for all to see, but if they are confirmed, it's just further proof of the incredible hardiness of life on Earth, and points to what's possible out there in the extreme conditions of space.
In a new automotive application, we have used convolutional neural networks (CNNs) to map the raw pixels from a front-facing camera to the steering commands for a self-driving car. This powerful end-to-end approach means that with minimum training data from humans, the system learns to steer, with or without lane markings, on both local roads and highways. The system can also operate in areas with unclear visual guidance such as parking lots or unpaved roads.
Figure 1: NVIDIA’s self-driving car in action.
We designed the end-to-end learning system using an NVIDIA DevBox running Torch 7 for training. An NVIDIA DRIVETM PXself-driving car computer, also with Torch 7, was used to determine where to drive—while operating at 30 frames per second (FPS). The system is trained to automatically learn the internal representations of necessary processing steps, such as detecting useful road features, with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. In contrast to methods using explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously.
We believe that end-to-end learning leads to better performance and smaller systems. Better performance results because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e. g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn’t automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps.
Convolutional Neural Networks to Process Visual Data
CNNs[1] have revolutionized the computational pattern recognition process[2]. Prior to the widespread adoption of CNNs, most pattern recognition tasks were performed using an initial stage of hand-crafted feature extraction followed by a classifier. The important breakthrough of CNNs is that features are now learned automatically from training examples. The CNN approach is especially powerful when applied to image recognition tasks because the convolution operation captures the 2D nature of images. By using the convolution kernels to scan an entire image, relatively few parameters need to be learned compared to the total number of operations.
While CNNs with learned features have been used commercially for over twenty years [3], their adoption has exploded in recent years because of two important developments.
First, large, labeled data sets such as the ImageNet Large Scale Visual Recognition Challenge (ILSVRC)[4] are now widely available for training and validation.
Second, CNN learning algorithms are now implemented on massively parallel graphics processing units (GPUs), tremendously accelerating learning and inference ability.
The CNNs that we describe here go beyond basic pattern recognition. We developed a system that learns the entire processing pipeline needed to steer an automobile. The groundwork for this project was actually done over 10 years ago in a Defense Advanced Research Projects Agency (DARPA) seedling project known as DARPA Autonomous Vehicle (DAVE)[5], in which a sub-scale radio control (RC) car drove through a junk-filled alley way. DAVE was trained on hours of human driving in similar, but not identical, environments. The training data included video from two cameras and the steering commands sent by a human operator.
In many ways, DAVE was inspired by the pioneering work of Pomerleau[6], who in 1989 built the Autonomous Land Vehicle in a Neural Network (ALVINN)system. ALVINN is a precursor to DAVE, and it provided the initial proof of concept that an end-to-end trained neural network might one day be capable of steering a car on public roads. DAVE demonstrated the potential of end-to-end learning, and indeed was used to justify starting the DARPA Learning Applied to Ground Robots (LAGR) program[7], but DAVE’s performance was not sufficiently reliable to provide a full alternative to the more modular approaches to off-road driving. (DAVE’s mean distance between crashes was about 20 meters in complex environments.)
About a year ago we started a new effort to improve on the original DAVE, and create a robust system for driving on public roads. The primary motivation for this work is to avoid the need to recognize specific human-designated features, such as lane markings, guard rails, or other cars, and to avoid having to create a collection of “if, then, else” rules, based on observation of these features. We are excited to share the preliminary results of this new effort, which is aptly named: DAVE–2.
The DAVE-2 System
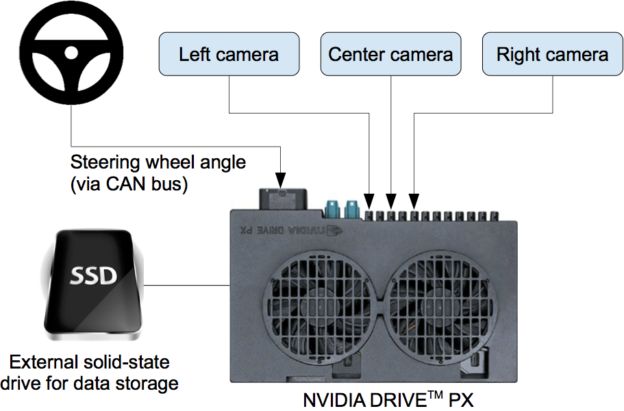
Figure 2: High-level view of the data collection system.
Figure 2 shows a simplified block diagram of the collection system for training data of DAVE-2. Three cameras are mounted behind the windshield of the data-acquisition car, and timestamped video from the cameras is captured simultaneously with the steering angle applied by the human driver. The steering command is obtained by tapping into the vehicle’s Controller Area Network (CAN) bus. In order to make our system independent of the car geometry, we represent the steering command as 1/r, where r is the turning radius in meters. We use 1/r instead of r to prevent a singularity when driving straight (the turning radius for driving straight is infinity). 1/r smoothly transitions through zero from left turns (negative values) to right turns (positive values).
Training data contains single images sampled from the video, paired with the corresponding steering command (1/r). Training with data from only the human driver is not sufficient; the network must also learn how to recover from any mistakes, or the car will slowly drift off the road. The training data is therefore augmented with additional images that show the car in different shifts from the center of the lane and rotations from the direction of the road.
The images for two specific off-center shifts can be obtained from the left and the right cameras. Additional shifts between the cameras and all rotations are simulated through viewpoint transformation of the image from the nearest camera. Precise viewpoint transformation requires 3D scene knowledge which we don’t have, so we approximate the transformation by assuming all points below the horizon are on flat ground, and all points above the horizon are infinitely far away. This works fine for flat terrain, but for a more complete rendering it introduces distortions for objects that stick above the ground, such as cars, poles, trees, and buildings. Fortunately these distortions don’t pose a significant problem for network training. The steering label for the transformed images is quickly adjusted to one that correctly steers the vehicle back to the desired location and orientation in two seconds.
Figure 3: Training the neural network.
Figure 3 shows a block diagram of our training system. Images are fed into a CNN that then computes a proposed steering command. The proposed command is compared to the desired command for that image, and the weights of the CNN are adjusted to bring the CNN output closer to the desired output. The weight adjustment is accomplished using back propagation as implemented in the Torch 7 machine learning package.
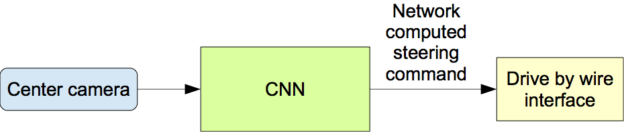
Once trained, the network is able to generate steering commands from the video images of a single center camera. Figure 4 shows this configuration.
Figure 4: The trained network is used to generate steering commands from a single front-facing center camera.
Data Collection
Training data was collected by driving on a wide variety of roads and in a diverse set of lighting and weather conditions. We gathered surface street data in central New Jersey and highway data from Illinois, Michigan, Pennsylvania, and New York. Other road types include two-lane roads (with and without lane markings), residential roads with parked cars, tunnels, and unpaved roads. Data was collected in clear, cloudy, foggy, snowy, and rainy weather, both day and night. In some instances, the sun was low in the sky, resulting in glare reflecting from the road surface and scattering from the windshield.
The data was acquired using either our drive-by-wire test vehicle, which is a 2016 Lincoln MKZ, or using a 2013 Ford Focus with cameras placed in similar positions to those in the Lincoln. Our system has no dependencies on any particular vehicle make or model. Drivers were encouraged to maintain full attentiveness, but otherwise drive as they usually do. As of March 28, 2016, about 72 hours of driving data was collected.
Network Architecture
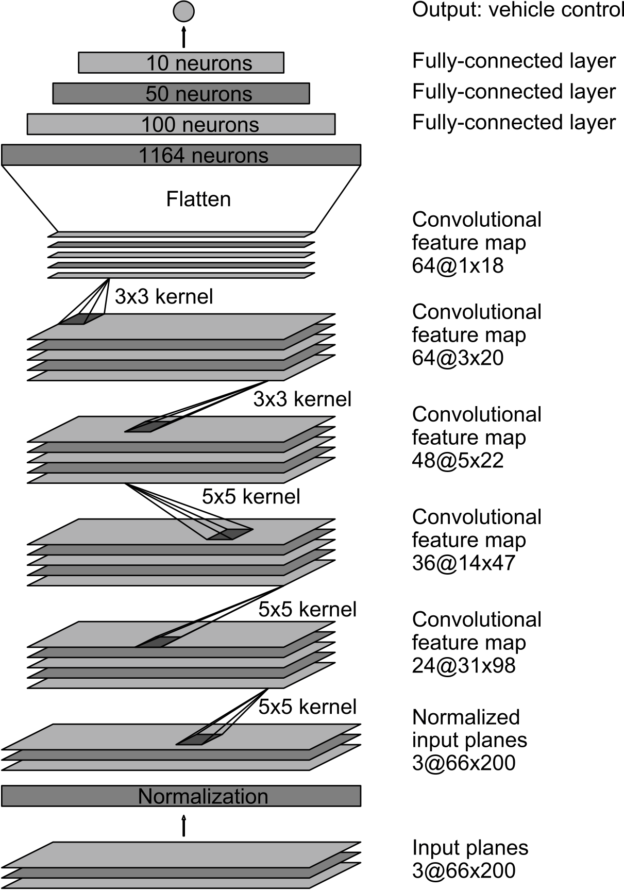
Figure 5: CNN architecture. The network has about 27 million connections and 250 thousand parameters.
We train the weights of our network to minimize the mean-squared error between the steering command output by the network, and either the command of the human driver or the adjusted steering command for off-center and rotated images (see “Augmentation”, later). Figure 5 shows the network architecture, which consists of 9 layers, including a normalization layer, 5 convolutional layers, and 3 fully connected layers. The input image is split into YUV planes and passed to the network.
The first layer of the network performs image normalization. The normalizer is hard-coded and is not adjusted in the learning process. Performing normalization in the network allows the normalization scheme to be altered with the network architecture, and to be accelerated via GPU processing.
The convolutional layers are designed to perform feature extraction, and are chosen empirically through a series of experiments that vary layer configurations. We then use strided convolutions in the first three convolutional layers with a 2×2 stride and a 5×5 kernel, and a non-strided convolution with a 3×3 kernel size in the final two convolutional layers.
We follow the five convolutional layers with three fully connected layers, leading to a final output control value which is the inverse-turning-radius. The fully connected layers are designed to function as a controller for steering, but we noted that by training the system end-to-end, it is not possible to make a clean break between which parts of the network function primarily as feature extractor, and which serve as controller.
Training Details
DATA SELECTION
The first step to training a neural network is selecting the frames to use. Our collected data is labeled with road type, weather condition, and the driver’s activity (staying in a lane, switching lanes, turning, and so forth). To train a CNN to do lane following, we simply select data where the driver is staying in a lane, and discard the rest. We then sample that video at 10 FPS because a higher sampling rate would include images that are highly similar, and thus not provide much additional useful information. To remove a bias towards driving straight the training data includes a higher proportion of frames that represent road curves.
AUGMENTATION
After selecting the final set of frames, we augment the data by adding artificial shifts and rotations to teach the network how to recover from a poor position or orientation. The magnitude of these perturbations is chosen randomly from a normal distribution. The distribution has zero mean, and the standard deviation is twice the standard deviation that we measured with human drivers. Artificially augmenting the data does add undesirable artifacts as the magnitude increases (as mentioned previously).
Simulation
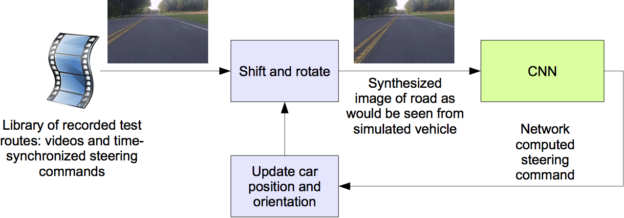
Before road-testing a trained CNN, we first evaluate the network’s performance in simulation. Figure 6 shows a simplified block diagram of the simulation system, and Figure 7 shows a screenshot of the simulator in interactive mode.
Figure 6: Block-diagram of the drive simulator.
The simulator takes prerecorded videos from a forward-facing on-board camera connected to a human-driven data-collection vehicle, and generates images that approximate what would appear if the CNN were instead steering the vehicle. These test videos are time-synchronized with the recorded steering commands generated by the human driver.
Since human drivers don’t drive in the center of the lane all the time, we must manually calibrate the lane’s center as it is associated with each frame in the video used by the simulator. We call this position the “ground truth”.
The simulator transforms the original images to account for departures from the ground truth. Note that this transformation also includes any discrepancy between the human driven path and the ground truth. The transformation is accomplished by the same methods as described previously.
The simulator accesses the recorded test video along with the synchronized steering commands that occurred when the video was captured. The simulator sends the first frame of the chosen test video, adjusted for any departures from the ground truth, to the input of the trained CNN, which then returns a steering command for that frame. The CNN steering commands as well as the recorded human-driver commands are fed into the dynamic model [7] of the vehicle to update the position and orientation of the simulated vehicle.
Figure 7: Screenshot of the simulator in interactive mode. See text for explanation of the performance metrics. The green area on the left is unknown because of the viewpoint transformation. The highlighted wide rectangle below the horizon is the area which is sent to the CNN.
The simulator then modifies the next frame in the test video so that the image appears as if the vehicle were at the position that resulted by following steering commands from the CNN. This new image is then fed to the CNN and the process repeats.
The simulator records the off-center distance (distance from the car to the lane center), the yaw, and the distance traveled by the virtual car. When the off-center distance exceeds one meter, a virtual human intervention is triggered, and the virtual vehicle position and orientation is reset to match the ground truth of the corresponding frame of the original test video.
Evaluation
We evaluate our networks in two steps: first in simulation, and then in on-road tests.
In simulation we have the networks provide steering commands in our simulator to an ensemble of prerecorded test routes that correspond to about a total of three hours and 100 miles of driving in Monmouth County, NJ. The test data was taken in diverse lighting and weather conditions and includes highways, local roads, and residential streets.
We estimate what percentage of the time the network could drive the car (autonomy) by counting the simulated human interventions that occur when the simulated vehicle departs from the center line by more than one meter. We assume that in real life an actual intervention would require a total of six seconds: this is the time required for a human to retake control of the vehicle, re-center it, and then restart the self-steering mode. We calculate the percentage autonomy by counting the number of interventions, multiplying by 6 seconds, dividing by the elapsed time of the simulated test, and then subtracting the result from 1:
Thus, if we had 10 interventions in 600 seconds, we would have an autonomy value of
ON-ROAD TESTS
After a trained network has demonstrated good performance in the simulator, the network is loaded on the DRIVE PX in our test car and taken out for a road test. For these tests we measure performance as the fraction of time during which the car performs autonomous steering. This time excludes lane changes and turns from one road to another. For a typical drive in Monmouth County NJ from our office in Holmdel to Atlantic Highlands, we are autonomous approximately 98% of the time. We also drove 10 miles on the Garden State Parkway (a multi-lane divided highway with on and off ramps) with zero intercepts.
Here is a video of our test car driving in diverse conditions.
Visualization of Internal CNN State
Figure 8: How the CNN “sees” an unpaved road. Top: subset of the camera image sent to the CNN. Bottom left: Activation of the first layer feature maps. Bottom right: Activation of the second layer feature maps. This demonstrates that the CNN learned to detect useful road features on its own, i. e., with only the human steering angle as training signal. We never explicitly trained it to detect the outlines of roads.
Figures 8 and 9 show the activations of the first two feature map layers for two different example inputs, an unpaved road and a forest. In case of the unpaved road, the feature map activations clearly show the outline of the road while in case of the forest the feature maps contain mostly noise, i. e., the CNN finds no useful information in this image.
This demonstrates that the CNN learned to detect useful road features on its own, i. e., with only the human steering angle as training signal. We never explicitly trained it to detect the outlines of roads, for example.
Figure 9: Example image with no road. The activations of the first two feature maps appear to contain mostly noise, i. e., the CNN doesn’t recognize any useful features in this image.
Conclusions
We have empirically demonstrated that CNNs are able to learn the entire task of lane and road following without manual decomposition into road o
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989. URL: http://yann.lecun.org/exdb/publis/pdf/lecun-89e.pdf.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks.
L. D. Jackel, D. Sharman, Stenard C. E., Strom B. I., , and D Zuckert. Optical character recognition for self-service banking. AT&T Technical Journal, 74(1):16–24, 1995.
Danwei Wang and Feng Qi. Trajectory planning for a four-wheel-steering vehicle. In Proceedings of the 2001 IEEE International Conference on Robotics & Automation, May 21–26 2001. URL: http://www.ntu.edu.sg/home/edwwang/confpapers/wdwicar01.pdf. rlane marking detection, semantic abstraction, path planning, and control. A small amount of training data from less than a hundred hours of driving was sufficient to train the car to operate in diverse conditions, on highways, local and residential roads in sunny, cloudy, and rainy conditions.
The CNN is able to learn meaningful road features from a very sparse training signal (steering alone).
The system learns for example to detect the outline of a road without the need of explicit labels during training.
More work is needed to improve the robustness of the network, to find methods to verify the robustness, and to improve visualization of the network-internal processing steps.
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backprop- agation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, Winter 1989. URL: http://yann.lecun.org/exdb/publis/pdf/lecun-89e.pdf.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1097–1105. Curran Associates, Inc., 2012. URL: http://papers.nips.cc/paper/ 4824-imagenet-classification-with-deep-convolutional-neural-networks. pdf.
L. D. Jackel, D. Sharman, Stenard C. E., Strom B. I., , and D Zuckert. Optical character recognition for self-service banking. AT&T Technical Journal, 74(1):16–24, 1995.
Large scale visual recognition challenge (ILSVRC). URL: http://www.image-net.org/ challenges/LSVRC/.
Net-Scale Technologies, Inc. Autonomous off-road vehicle control using end-to-end learning, July 2004. Final technical report. URL: http://net-scale.com/doc/net-scale-dave-report.pdf.
Dean A. Pomerleau. ALVINN, an autonomous land vehicle in a neural network. Technical report, Carnegie Mellon University, 1989. URL: http://repository.cmu.edu/cgi/viewcontent. cgi?article=2874&context=compsci.
Danwei Wang and Feng Qi. Trajectory planning for a four-wheel-steering vehicle. In Proceedings of the 2001 IEEE International Conference on Robotics & Automation, May 21–26 2001. URL: http: //www.ntu.edu.sg/home/edwwang/confpapers/wdwicar01.pdf.

































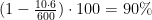


{kind=link}